通过学习imooc课程《JavaScript正则表达式》,对视频教学内容做一个知识整理。
一个正则表达式在线工具:
JavaScript 通过内置对象RegExp支持正则表达式,有两种方法实例化RegExp对象:
- 字面量 eg: var reg = /\bis\b/g;
- 构造函数 eg: var reg = new RegExp("/\bis\b/","g" );
1.修饰符
- g:global全文搜索,不添加,搜索到第一个匹配停止;
- i:ignore case忽略大小写;
- m:multiple lines多行搜索;
2.元字符
正则表达式有两种基本字符类型组成:
- 原义文本字符,即要找什么就是什么,要找a就直接写a,找123就直接写123;
- 元字符,有特殊含义的非字母字符:* ? + $ ^ . | \ ( ) { } [ ];
其他的还有:
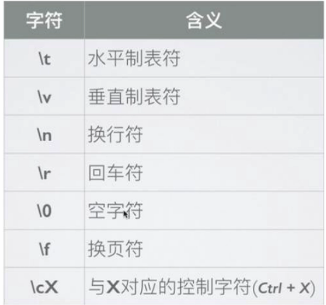
3. 字符类
一般情况正则表达式一个字符对应字符串一个字符,eg 表达式ab\t含义是 "ab" tab制表符;一般由元字符 [ ] 来构建一个简单的类,不是特指某个字符,eg [abc]把字符a或b或c归为一类;在[ ]里面加 ^ 表示取反,eg [^abc]代表不要有a或b或c;
4.范围类
用[a-zA-Z0-9]来代表a到z或A到Z货0到9中任意字符;
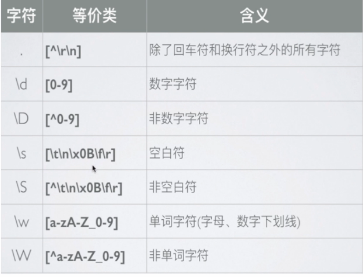
5.预定义类
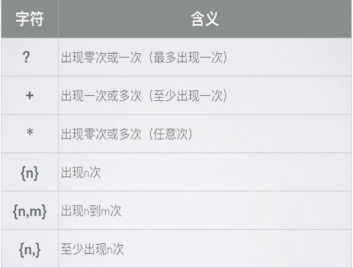
6.量词
再有很常用的 ^n 匹配任何开头为 n 的字符串 ; n$匹配任何结尾为 n 的字符串。
还有一个易混淆的,?=n 匹配任何其后紧接指定字符串 n 的字符串。就是说要找到的这个字符后面一定要跟字符n
eg var reg = "a1b1c1ddeeff";
reg.replace(/\w(?=\d)/g,"Y");
结果是"Y1Y1Y1ddeeff" 与之相反的就是 !?=n;
7.贪婪模式、非贪婪模式
正则表达式在默认下是尽可能多的匹配,eg "123456789".replace(/\d{2,5}/g,"X"); 结果是X6789,默认贪婪模式,以{2,5}范围中最大的为标准匹配。
要设置成非贪婪模式可以"123456789".replace(/\d{2,5}?/g,"X");结果为XXXX9,即按{2,5}中最小的2来匹配,12,34,56,78都匹配成功变成X,剩下9没有匹配成功
8.分组
使用()可以达到分组功能,使量词作用于分组,eg "a1b1c1d2".replace(/[a-z]\d{3}/g,'x');这里{3}是直接作用与最接近的\d,即找[a-z]然后连续出现3个数字,"a1b1c1d2".replace(/([a-z]\d){3}/g,'x');这样就能找到连续出现三次(一个字母加一个数字),就是"a1b1c1"这个字符串了;
9.对象属性
- global(只可读,不可写)
- ignoreCase(只可读,不可写)
- multiline(只可读,不可写)
- lastIndex 一个整数,标示开始下一次匹配的字符位置。(理解这个请看下面方法test())
- source 正则表达式的源文本。
10.方法
- test() 检索字符串中指定的值。返回 true 或 false。
- exec() 检索字符串中指定的值。返回找到的值,并确定其位置。
- compile() 编译正则表达式。
test(): eg var reg = /\w/g; reg.test("ab");结果是true,但多执行几次会发现
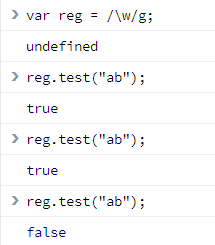
最后一个结果变成false,这其实和RegExp属性lastIndex有关,
var reg = /\w/g;while(reg.test('ab')){ console.log(reg.lastIndex);} 结果是1,2,这是因为第一次test会匹配到a,这时lastIndex就是这个字符a的下一位,即b的位置1,接着test还会继续向后面匹配,轮到这个b,这是lastIndex就是b后面的位置2,之后会重置为0,从头开始循环。要避免这种test出现不稳定输出,可以直接/\w/g.test("ab");
exec() :返回一个数组,其中存放匹配的结果。如果未找到匹配,则返回值为 null。借用w3school上的话,如果 exec() 找到了匹配的文本,则返回一个结果数组。否则,返回 null。此数组的第 0 个元素是与正则表达式相匹配的文本,第 1 个元素是与 RegExpObject 的第 1 个子表达式相匹配的文本(如果有的话),第 2 个元素是与 RegExpObject 的第 2 个子表达式相匹配的文本(如果有的话),以此类推。
看代码:
var reg = /\d(\w)(\w)d/;var str = "1ax2by3cz4d5e";var ret = reg.exec(str);console.log(ret);
输出: ["1ax2", "a", "x"]
这里返回的数组第一个就是匹配到的1a2,然后第二和第三个数组就是1a2中间的a和x,因为/\d(\w)\d/里面的子表达式就是(\w)(\w);
同样的来看正则对象的lastIndex属性,以及匹配结果的数组的index属性:
var reg = /\d(\w)(\w)\d/g;var str = "$1ax2by3cz4dd5ee";while(ret = reg.exec(str)){ console.log(reg.lastIndex + '\t' + ret.index + '\t' + ret);} 输出: "5 1 1ax2,a,x" "11 7 3cz4,c,z"
第一个:5,指第一次匹配后reg对象的lastIndex(红色后面的位置),1指的是exec()方法返回的位置,$后面开始匹配到的,所以是1;
第二个:11,指第一次匹配后reg对象的lastIndex(蓝色后面的位置),7指exec()方法返回的位置,y后面开始匹配到的,所以是7;
compile():我的理解是可以修改正则表达式,看代码
function CompileDemo(){ var rs; var s = "AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPp" var r = new RegExp("[A-Z]", "g"); var a1 = s.match(r); r.compile("[a-z]", "g"); var a2 = s.match(r); return(a1 + "\n" + a2);}console.log(CompileDemo()); 输出: "A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p"
11.支持正则表达式的 String 对象的方法
- search() 检索与正则表达式相匹配的值。(简单的就是找到匹配字符的开始位置)
- match() 找到一个或多个正则表达式的匹配。(与exec()有些许相似,只是exec()返回的内容更加细节)
- replace() 替换与正则表达式匹配的子串。(这个不多说)
- split() 把字符串分割为字符串数组。(这个也容易,就是注意别忘了)
(这里要注意10 和 11 是完全对应不同对象的方法,一个是RegExp对象的方法,一个是String对象的方法)
这部分主要在JavaScript string对象部分有学习到,可以参考